A ChatGPT új verziójának bemutatkozásával óriásit nőtt a befektetők körében a mesterséges intelligencia iránti érdeklődés. Az alábbiakhoz hasonló kérdéseket heti gyakorisággal kapok olvasóinktól:
„Mostanában sokat hallani a mesterséges intelligenciáról, mit gondol, a tőzsdén is átveszi a kereskedők helyét?”
A mesterséges intelligencia eljárások mögötti algoritmusokat egy korábbi cikkünkben már megbeszéltük (lásd itt). Érdemes lehet a hivatkozott leírást is tanulmányozni a cikkünkben leírtak megértéséhez. A rendelkezésünkre álló adatok azonban azt mutatják, hogy nagyon messze van az a világ, amikor a mesterséges intelligencia átveszi az aktív alapkezelők, aktív kereskedők szerepét. Az alábbiakban a témával kapcsolatos 27 vizsgálat tanulságait összegezzük. Témáink:
- Milyen problémái vannak az aktív kereskedésnek?
- Milyen hozamokat ér el jelenleg a mesterséges intelligencia?
- Mi a magyarázat a mesterséges intelligencia gyenge teljesítményére?
- Mit kezd a mesterséges intelligencia a technikai elemzés jelzéseivel?
- Mesterséges intelligencia segíthet a gyorsjelentések értelmezésében
- Mire számíthatsz, ha a ChatGPT ad pénzügyi tanácsot?
- A ChatGPT jobban értelmezi a Fed sajtótájékoztatókat..
- ChatGPT és a részvényárak jóslása
Milyen problémái vannak az aktív kereskedésnek?
Az első probléma a piaci környezet és az aktív alapkezelők teljesítménye, hiszen a ma létező aktív alapkezelési iparág nem képes felülteljesíteni, nem képes a tőzsdeindex hozamánál nagyobb hozamot tartósan elérni. Ha vannak is felülteljesítő alapkezelők, nincs bizonyíték arra, hogy a felülteljesítés oka a szakértelem és nem a véletlen. Sajnos ezeket a sorokat tucatnyi kutatás támasztja alá, melyekről itt beszéltünk bővebben, de elég csak rápillantanunk az alábbi grafikonra. Bár három éves összevetésben, bizonyos kategóriákban jobb a befektetési alapok teljesítménye, azonban 10-20 éves hozamokat vizsgálva a többségük nem képes megverni a tőzsdeindexet, lásd alábbi képen.
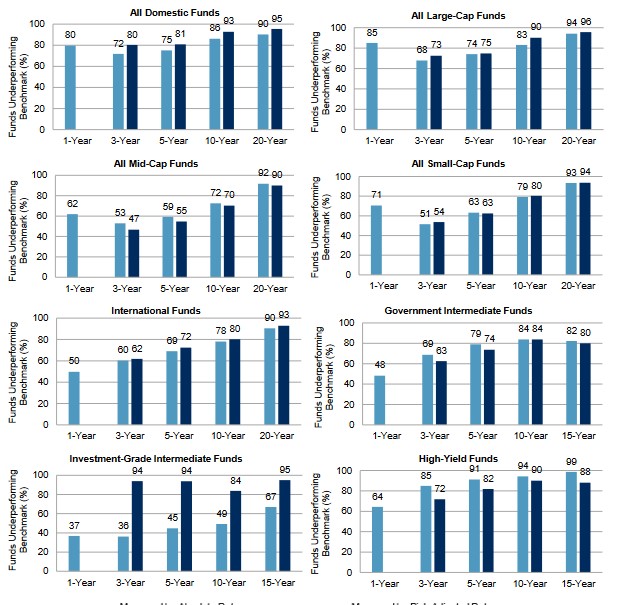
Forrás: SPIVA US Scrocard
A mai világban az információhoz való hozzáférés (néhány kivételtől eltekintve) teljesen demokratizált. Bárki megvásárolhatja azokat a nagy adatbázisokat, melyekkel az aktív alapkezelők dolgoznak, sokkal nehezebb belső, mások által nem ismert információhoz hozzájutni, és ahogy a BlackRock vezetője, Mark Wiseman fogalmazott:
“The old way of people sitting in a room picking stocks, thinking they are smarter than the next guy – that does not exist anymore.”
Azaz ma már nem létezik az a világ, melyben néhány alapkezelő részvényeket kiválogatva összerak egy portfóliót abban a hitben, hogy ők okosabbak a többieknél. Ilyen alapkezelők persze vannak, a magyar piacon is, de felülteljesíteni nem tudnak. A mesterséges intelligenciának tehát egy olyan piaci környezetben kell piacra lépnie, ahol ma már bárki számára elérhetők a nagy adatbázisok, és különböző eszközökkel, akár fejlett nyelvi modellekkel képes lehet feldolgozni ezeket a nagy adatbázisokat. Ez tehát az első problémája a mesterséges intelligenciát használó rendszereknek.
Milyen hozamokat ér el jelenleg a mesterséges intelligencia?
De beszéljünk a konkrétumokról is, egy 2021-es vizsgálatról, melyben az elmúlt 20 év mesterséges intelligencián alapuló tőzsdén alkalmazott rendszereit vizsgálták meg. A hivatkozott metaanalízisben 27, a témával kapcsolatos kutatást összegeztek. A fontosabb megállapításaik a következők voltak:
- A legtöbb kutatásban különböző változatokkal, paraméterekkel futtatták a gépi tanuláson alapuló algoritmusokat. A különböző változatokat párhuzamosan futtatták, és szinte minden vizsgálatban csak a legjobb változatot emelték ki. A nem optimális változatokat kihagyták. Erre mondjuk azt, hogy addig dolgoztak az adatokon, amíg a várt eredményeket megkapták. Természetesen ezek az ún. overfitted rendszerek csak in sample adatokon működnek és out of sample adatokon (a valóságban) nem.
- A vizsgált modellek megbízhatósága, pontossága rendkívül magas volt, 95 százalékos. Ugyanakkor tudjuk azt, hogy az eredményeket nemcsak a találati arány határozza meg, hiszen a martingale-stratégiák találati aránya is rendkívül magas, akár 95-99 százalékos, de az 1-5 százalékos veszteséges ügyleteken elúszik a tőke 40-99 százaléka.
- A legtöbb vizsgálatban nem vették figyelembe a kereskedés költségeit, és sajnos nagyon sokszor a többlethozam nagy része eltűnik, ha figyelembe vesszük a kereskedés költségeit.
- A 27 kutatásban szereplő mesterséges intelligencia algoritmusa egy fekete doboz, azaz semmiféle rálátásunk nincs arra, hogyan működik, azt sem tudhatjuk, hogy képes-e a rendszer gépi úton tanulni.
- Az algoritmusok szűk körét tesztelték vissza nyilvánosan elérhető adatokon. Ezeken az adatokon nagyrészt alulteljesítettek az AI-támogatott algoritmusok.
- Az idő előrehaladtával nem nőtt az AI-algoritmusok találati aránya, pedig ezt várhatnánk egy tanulni tudó rendszertől.
A szerzők több, a valóságban hedge fundok által futtatott AI-algoritmusok eredményeit is megvizsgálták:
- Az Eurekahedge hedge fund 2011-2022 közötti időszakon halmozott hozamban alulteljesített. A passzív befektetők halmozott hozama 210 százalékkal magasabb volt az időszakon.
- A Preqin’s AI hedge fund 2016-2019 közötti időszakon 27 százalék hozamot ért el, de ezen időszak alatt az amerikai részvénypiacon 65 százalék hozam keletkezett.
- Az Aidya, a mesterséges intelligencia iparágban legendának számító Ben Goertzel fejlesztése. Az AI az első kereskedési napon 12 százalék hozamot generált, majd egy éven belül a projektet abbahagyták a gyenge teljesítmény miatt.
- A Sentient Technologies hedge fund AI támogatott algoritmusa 2017-ben 4 százalék, 2018-ban 0% hozamot ért el, majd a projektet abbahagyták.
Léteznek olyan ETF alapok is, melyek a mesterséges intelligencia alapján alakítják a portfóliójukat. Az alapok konkrét nevének említése nélkül nézzük az eredményeket:
- Az egyik egy global makró típusú AI ETF, mely 2018-ban indult, de 2018, 2019 években nem tudott nyereséget termelni, majd az alapkezelést befejezték.
- Egy másik ETF alap, az EquBot nevű AI segítségével kezeli a portfóliót. Az IBM Watson támogatásával működő algoritmus 2017-2023 közötti időszakon évi 6,7 százalékos hozamot ért el, 23 százalékos szórás mellet. Ezen időszak alatt a teljes részvénypiacba passzívan befektetők 11,2 százalékos hozamot érhettek el 18,5 százalékos szórás mellett.
Az alábbi képen az egyik legrégebbi, mesterséges intelligenciát (IBM Watson) használó ETF alap eredményét (piros) viszonyíthatjuk a teljes amerikai részvénypiachoz (szürke) és a technológiai szektorhoz (zöld)

forrás: Dimensional
A fenti eredményeket a metaanalízis szerzői a következők szerint összegzik:
- Nincs bizonyíték arra, hogy bármely gépi tanuláson alapuló algoritmus, befektetési alap kiemelkedő hozamot biztosított volna.
- Minden vizsgált alap alulteljesítette a benchmarkként használt tőzsdeindexeket.
- Nem látható át, hogyan jutnak el az algoritmusok az előrejelzéstől a portfóliókialakításig.
- Ez ugyan kísérleti tevékenység során elfogadható, de nagyon kockázatos a valóságban, valódi pénz befektetése mellett.
Mi a magyarázat a mesterséges intelligencia gyenge teljesítményére?
A fentiek megértéséhez látni kell azt, hogy az aktív vagyonkezelés egy zéró összegű játék. Különösen igaz ez rövid távon, hiszen rövid távon a befektetési eszközökben levő vagyonmennyiség megegyezik a befektetők által a részvényvásárlásra költött összeggel. Ettől a hosszú táv azért tér el, mert a tőzsdei társaságok értéket teremtenek, növekszik a profitjuk, így a befektetők tulajdonosként részesülnek a jövőbeni nyereségből. Ugyanakkor rövid távon sokkal inkább egy versenyhez hasonlítható a tőzsdei kereskedés, és ma már sokkal gyorsabban beépülnek a piaci árba az új információk, ahogy az új kutatások által felderített összefüggések is. Ehhez tegyük hozzá, hogy az egyéni befektetők már régóta használnak különböző AI-támogatott megoldásokat, melyekkel nagy mennyiségű adatot gyorsan dolgoznak fel, és döntéseiket támogatják ezekkel az adatokkal. Csak példaképpen, a ChatGPT és más nyelvi modelleken alapuló gyorsjelentés-, hír- és hangulat-értelmezésre évek óta léteznek a piacon igénybe vehető szolgáltatások.
Továbbá a mesterséges intelligencia, a gépi tanulás alapú rendszerek akkor képesek jó előrejelzéseket készíteni, ha az előrejelzéshez felhasznált adatok stabilak. Ez pont nem igaz a gazdasági adatokra, melyeknél a gazdasági környezettel együtt változik az összefüggések erőssége. Ráadásul a tőzsdei árakra különböző tényezők eltérő hatást gyakorolnak egy rendkívül összetett rendszerben. Az önvezető autókon lehetne ezt a problémát jól szemléltetni. Az önvezető algoritmusok számára pontosan definiálva van, hogy mit jelentenek a táblák, a felfestések. Ezek a jelek vezérlik az algoritmust, ezek a bemenő adatok határozzák meg a program kimenetelét. Ugyanez igaz a kereskedni, befektetni tanuló mesterséges intelligenciára is. A gazdasági rendszerben is vannak szabályok, de ezek a szabályok naponta változnak. Könnyen megérhetjük, hogy mi a probléma az előrejelzéssel ebben az esetben, ha arra gondolunk, hogyan működne egy önvezető algoritmus, ha a közlekedési jeleket, szabályokat naponta változtatnák.
Mit kezd a mesterséges intelligencia a technikai elemzés jelzéseivel?
A technikai elemzés alapvetően abból a feltételezésből indul ki, hogy a múltbeli ár és a jövőbeni ár között van kapcsolat. Ez azonban ellentmond az ismert tőkepiaci modellek állításának, melyek közül ha a hatékony piacok bármely formáját nézzük (gyenge, erős, félig erős), mindegyiknek az az alapfelvetése, hogy a múltbeli és a jövőbeni ár független. Pontosan ezért a technikai elemzés mellőzött területe az akadémikus kutatásoknak, sokkal inkább a „voodoo finance” kategóriába sorolható. Ugyanakkor számos vizsgálat utal arra, hogy a technikai elemzés eszközei hasznos információt hordoznak. Ezekről a vizsgálatokról korábbi cikkeinkben (lásd az alábbi hivatkozásokat és az alábbi elődadást) készítettem összefoglalót:
- 29 kutatás összegzése a mozgóátlag tőzsdestratégiákról
- Van bizonyíték a technikai elemzés, árfolyam-alakzatok működésére?
- A japán gyertyák használhatatlan eszközök?
- Van bizonyíték az indikátorok hatásosságára a tőzsdén?
Az Application of Machine Learning in Algorithmic Investment Strategies cím alatt elérhető, cikkünkben tárgyalásra kerülő tanulmányban a technikai elemzés különböző árindkátorait (egyetlen bemenő paraméterük az instrumentum ára) vizsgálták. Ezek az alábbiak voltak:
- Egyszerű mozgóátlagok (jelölés a továbbiakban: SMA), lásd itt.
- MACD indikátor (MACD), lásd itt.
- Stochastic oszcillátor (SO), lásd itt.
- RSI indikátor (RSI), lásd itt.
- Williams Percent Range (WPR)
Amikor a mesterséges intelligenciáról hallunk, akkor sokan azt gondolják, hogy egy emberhez hasonló módon gondolkodni képes algoritmusról van szó, melynek olyan elvont gondolatai vannak, mint nekünk. Ahogy erről a témával kapcsolatos cikkeinkben (itt és itt) már beszéltünk, erről szó sincs, a mesterséges intelligencia ma gyakorlatilag egyet jelent különböző statisztikai módszerek futtatásán, mely valóban hasonlít arra, ahogy az ember elemzi az adatokat egy döntéshelyzet során.
Ugyanakkor a fentiek nem azt jelentik, hogy az AI sokkal pontosabb jeleket talál az adatokban, hiszen a hagyományos optimalizációnak az a lényege, hogy az összes lehetséges kombinációban megvizsgálja a stratégiát. Aki már csinált ilyen optimalizációt (erre bármely stratégia teszter, például a metatrader is képes), az tudja, hogy mi ezzel a gond. Bonyolultabb esetekben évekig tartó optimalizációval találhatjuk meg az optimális paramétereket. Ugyanakkor statisztikai módszerekkel számos alternatíva már a tesztelés első pillanatában kizárható, és nincs szükség arra, hogy végig számoljuk azokat. Gondoljunk arra a hétköznapi példára, melyben az a feladatunk, hogy B városba eljussunk délután három órára a lehető legolcsóbb módon. Ebben a döntési helyzetben az emberi agy azonnal kizár számos alternatívát, például roller, gördeszka, gyaloglás, helikopter. Egész egyszerűen azon indokkal, hogy „nem így szoktuk” a problémát megoldani, így végül az alternatívák száma gyorsan lecsökken 3-4 változatra (busz, vonat, autó, taxi).
Kicsit leegyszerűsítve, de a mesterséges intelligenciának hívott statisztikai eljárások is a fentieket csinálják az adatokkal. Egyszerűsítéseket végeznek, így például a fenti tanulmányban 20 éves adatsoron (2002-2023), a WIG20, DAX, S&P500, BUX, PX, SOFIX, OMXR, OMXT, OMXV tőzsdeindexeken, 5 indikátoron (SMA, MACD, RSI, SO, WPR) és 8 különböző gépi tanuláson alapuló algoritmus segítségével 5 óra alatt befejezték a számításokat.
A tanulmányban az alábbi algoritmusokat használták:
- Neurális hálózatok (NN)
- K nearest neighbor (KNN)
- Random forest (RF)
- Regression Trees (RT)
- Naive Bayes (NB)
- Bayesian Generalized Linear Model (BGLM)
- Support Vector Machine Linear (SVML)
- Support Vector Machine Polynomial (SVMP)
A fentiek közül talán a legismertebb a neurális hálózatok, hiszen az AI tavalyi sikerei nagyrészt a mélytanulás és a mögötte levő neurális hálózatok tökéletesítésének köszönhetők. Részletesen az eljárásról a "Közeleg az újabb AI-tél" cím alatti cikkünkben beszéltünk. A technikai elemzés viszonyában azonban a neurális hálózatoknak egy egyszerűbb, a rejtett rétegében egyetlen rétegből álló változatával dolgoznak. Ez az ún. Extreme Learning Machne (ELM), mely Rajashree Dash és Pradipta Kishore Dash sokat idézett 2016-os munkáján alapul.
A K nearest neighbor egy sokkal régebbi eljárás (Altman 1991-es munkájában részvénypiacon alkalmazták, de eredetileg 1951-ben kidolgozott eljárás). Ennek lényege, hogy egy meghatározott megbízhatóság alapján kategorizáljuk az adatokat, ebben az esetben az indikátorok jelzéseit egy bizonyos találati arány alatt elvetjük.
A random forest lényege, hogy döntési fák sokaságát (decession trees) hozzuk létre, de a hagyományos döntési fáktól eltérően véletlenszerűen alakítjuk ki a döntési helyzetek, sorrendek kombinációját, majd megnézzük, melyik vezet eredményre. A regression tree olyan döntési fákat jelöl, ahol az adatok közötti összefüggéseket lineáris regresszióval állapítjuk meg. A support vector machine eljárások lényege, hogy találjunk egy olyan hipersíkot (hyperplane), mellyel az egyes változatok kategorizálhatók. A hipersík egy kétváltozós modellben egyenes lenne, de ha a változók száma több, akkor n dimenziós tömbök alapján kell az adatokat szétválasztani.
A fenti algoritmusokkal úgy vizsgálták meg az adatokat, hogy minden évben elkülönítettek egy in sample adatkört, mely 200 kereskedési nap adatát használta fel. Ezen az in sample adatkörön zajlott a betanulás, majd a következő hónapban (ez tette ki az out of sample adatkört) a betanult összefüggések alapján kereskedtek az algoritmussal. Ezt újabb 200 napos betanulás, majd újabb egy hónapos kereskedés követte, egészen addig, amíg a 2002-es indulástól el nem értünk 2023-ig.
Az alábbi ábrán a DAX indexen elért eredményeket láthatod. A különböző színek az egyes AI-algoritmusokat jelölik, de piros színnel megtalálható a vedd meg és tartsd technika eredménye, azaz nem időzítünk, folyamatosan befektetve vagyunk.

forrás: Application of Machine Learning..
Grafikus formában meglehetősen nehéz áttekinteni az adatokat, nézzük meg táblázatos formában. A táblázat első oszlopában a vedd meg és tartsd technika eredményei, a többi oszlopban a különböző gépi tanuláson alapuló eljárás eredménye látható. A CAGR mutatná az összetett éves növekedést, gyakorlatilag a hozam évesített formában. A hozam önmagában azonban nem elegendő, hiszen nem látjuk a mögötte levő kockázatot, így a sharpe-rátára lenne célszerű fókuszálni, mely egységnyi kockázatra vetítve mutatja a többlethozamot, azaz a magasabb érték jobb stratégiát jelöl. Az MDD sorban a maximális visszaesést látjuk, míg az IR a hozam és a maximális visszaesés összevetése. A legjobb stratégiát tehát a legmagasabb sharpe és IR kombinációja adja.

forrás: Application of Machine Learning..
Az alábbi táblázatban az amerikai tőzsdeindexen visszatesztelt eredmények láthatók.

forrás: Application of Machine Learning..
Az alábbi táblázat mutatja, hogy IR-mutató szerint, melyek a legjobb gépi tanulás algoritmusok. Amíg például a DAX esetében a Regression Trees (RT), addig a BUX indexen a Bayesian Generalized Linear Model (BGLM) hozta az optimális eredményt. Ebben a táblázatban azt a változatot látjuk, amikor az indikátor paramétereket az eredeti értékről lefelé haladva csökkentjük. Más eredményeket kapunk akkor, ha a paramétereket növeljük, de az is eltérő eredményt ad, ha az in sample adatvizsgálat hosszát (200 nap) növeljük, csökkentjük, ahogy az out of sample adatkör növelése, csökkentése is változtat az eredményeken. Ezeket az eredményeket nem másolom be, de a tanulmányban megtalálhatók.

forrás: Application of Machine Learning..
Az eredmények azt mutatják, hogy a vizsgált árindkátorok (MACD, SMA, RSI, SO, WPR) hozzájárulhatnak a vedd meg és tartsd technika felülteljesítéséhez. Eltérő eredményeket kapunk annak függvényében, hogy milyen eljárással keressük meg a fenti indikátorok optimális hozamot (IR-mutató alapján) eredményező paramétereit. Azt mutatják az adatok, hogy az S&P500 és a WIG20 indexen a Polynomial Support Vector Machine model, a DAX indexen a Linear Support Vector Machine model, míg a több index esetében a Linear Support Vector Machine algoritmusok biztosították a legmagasabb hozamot (egységnyi kockázatra vetítve). Amint azonban az indikátorok paramétereit változtatni kezdtünk (például RSI 14-es periódusát, egyesével csökkentettük, növeltük), már más módszerek bizonyultak hatékonynak.
A kutatás elsődleges hipotézise az volt, hogy a gépi tanuláson alapuló kvantitatív befektetési stratégiák magasabb egységnyi kockázatra jutó hozamot biztosítanak. Ezt a hipotézist nem lehet a fentiek alapján elutasítani, de ez nem feltétlenül jelenti azt, hogy a gyakorlati kereskedésben a fentieknek rendkívüli haszna lenne. Ugyanis egy módszer akkor robusztus, ha a paraméterek kismértékű változtatására nem érzékeny az eredmények tekintetében. Itt pedig pont azt láthatjuk. Ez pedig egyébként is a technikai elemzés indikátorainak a fő problémája, azaz különböző időszakokban különböző paraméterekkel működik jól az indikátor. A kereskedő a múltbeli adatokon hagyományosan optimalizálja vagy gépi tanulással megállapítja az ideális paramétereket, de ezek a jövőben megváltoznak, és nem optimális eredményt adnak. Sajnos az ilyen optimalizálás során nagyon sokszor elkövetjük az overfitting hibáját. A gépi tanuláson alapuló algoritmusok tehát hasznos eszközei lehetnek a tőzsdei kereskedőnek, de alapvetően nem oldják meg a technikai elemzés eredeti problémáját, viszont mindenképpen nagy előnye a módszereknek, hogy a múltbeli időszak optimális paramétereit sokkal gyorsabban, kisebb erőforrással megtalálják, mint a hagyományos, minden kombinációt végigszámoló algoritmusok. A teljes képhez hozzátartozik, hogy a mesterséges intelligenciát nemcsak a technikai elemzés, hanem a részvénypiac statisztikai elemzésen alapuló kereskedési módszereinél is használjuk. Azonban a fentiekből is sejthető, hogy nagyon messze vagyunk az olyan mesterséges intelligenciát alkalmazó algoritmusoktól, melyek out of sample adatokon stabilan jó eredményt képesek hozni. A témához kapcsolódóan egy korábbi előadásunkban kitértem arra, hogy az AI támogatott hedge fundok és ETF alapoknak milyen eredményei lettek valós (nem backtest) körülmények között.
Mesterséges intelligencia segíthet a gyorsjelentések értelmezésében
A Can AI Read the Minds of Corporate Executives? alatti vizsgálat nevesít számos módszert, melyekkel automatikusan értelmezhető egy gyorsjelentés. Előljáróban annyit kell megértenünk, hogy a tőzsdei társaságok negyedévente (ez a 10-Q) és évente (10 K) tesznek közzé beszámolót a működésükről. A gyorsjelentések jelentős piacmozgató eseménynek tekinthetők. Nagyon sok technika foglalkozik a gyorsjelentések kereskedésével, akár technikai elemzés területéről (lásd itt), akár a kvantitatív módszerek területéről (lásd itt). Rendelkezésünkre állnak vizsgálatok, melyek korábbi nyelvi modellek segítségével állapították meg, hogy a gyorsjelentések tartalmi változásai, vagy a pozitív szavak előfordulási gyakoriság összefüggésbe hozható a jövőbeni hozammal (itt beszéltünk ezekről).
A gyorsjelentések automatizált értelmezésére azért van szükség, mert egyrészt nagyon hosszú és számos gyorsjelentés jelenik meg, melyet objektíven értékelni nehéz. Másrészt az automatikus szövegfeldolgozás lehetővé teszi azt, hogy megbecsüljük várható-e meglepetés, milyen mértékű lesz a meglepetés a következő gyorsjelentés során. A meglepetés az elemzők által várt nyereségadat és a ténylegesen közzétett nyereség különbsége. Eszerint tehát ha nagy pozitív meglepetést várunk, akkor vételi ügyletet kötünk, ellenkező esetben pedig short ügyletet. Leegyszerűsítve ez a lényege ezeknek a kereskedési stratégiáknak. Azonban ezek a klasszikus nyelvi modellek nem tudják tökéletesen értelmezni a szövegeket, de a most publikálásra került tanulmány arra tett kísérletet, hogy a fejlett nyelvi modellek új generációját tanítsa be erre a célra.
A legkezdetlegesebb alkalmazásokban előre meghatározták a negatív és pozitív szavakat és a rendszer ezen szólista alapján értékelte a gyorsjelentéseket. A legkorábbi modellek a Harvard IV-4 szótárt használták erre a célra, de 2011-ben Loughran és McDonald összeállított egy a gyorsjelentésekre specializált szótárt, mellyel sokkal pontosabban lehetett értelmezni a gyorsjelentéseket.
A fejlett nyelvi modellek azonban szakítanak ezzel a szemlélettel, és nem csak szavakat vizsgálnak, hanem képes mondatokat, kifejezéseket értelmezni, kapcsolatot keresni szavak, mondatok között a szövegekben. Nem meglepő, hogy pontosabb eredményeket lehet elérni a fejlett nyelvi modellekkel, és például a ChatGPT 3-as és 4-es verziója között is óriási különbség mutatható ki.
A ChatGPT azonban egy általános célra használható nyelvi modell, de léteznek kifejezetten olyan modellek is, melyek betanítása pénzügyi anyagokon történt. Ilyen például a Google által fejlesztett BERT, és a fenti vizsgálat szerzői a BERT rendszerét finomították, optimalizálták kifejezetten a gyorsjelentések értelmezésére, így jött létre a Fine Tune BERT, azaz az FtBERT.
A vizsgálatban 1993-2021 közötti adatokat dolgoztak fel, és az amerikai tőzsdei társaságok Edgar rendszerében elérhető 10-K és 10-Q jelentéseit tekintették át. Az FtBERT 1993-2002 közötti időszakon lett betanítva, majd az ezt követő időszakban zajlottak az out of sample tesztelések. Az algoritmus feladata az volt, hogy a közzétett jelentések elemzéséből állapítsa meg, hogy a következő gyorsjelentés során várható-e nagy pozitív vagy nagy negatív meglepetés a nyereség vonatkozásában. Ezen jelzések alapján long-short portfóliókat alakítottak ki, melyek lényege, hogy a long portfólióba kerülnek azok a részvények, melyeknél a legnagyobb pozitív meglepetés várható, és a short portfólióba azok a részvények kerülnek, ahol a legnagyobb negatív meglepetésre számít az algoritmus.
A vizsgálatból kiderült, hogy a pozitív meglepetéseket tartalmazó portfólió átlagosan havi 0,56 százalékponttal (évi 6,74 százalékponttal) felülteljesíti a negatív meglepetést tartalmazó portfóliókat, azaz az FtBERT előrejelző képessége hasznosítható. Az alábbi grafikonon látható annak a portfóliónak az eredménye, amely mindig az FtBERT által leginkább vételre ajánlott (legnagyobb pozitív meglepetés) részvényekből áll (FtBert HI néven), és követhetjük annak a portfóliónak az eredményét is, melynél a legnagyobb negatív meglepetés volt várható (FtBert LO néven). A FrozenBERT és az MD&A más típusú algoritmusok, az S&P500 index az amerikai részvénypiac történő befektetés eredményét szemlélteti. Költségekkel nem számoltak a vizsgálatban.

A fenti vizsgálat több dologra is rávilágít. Egyrészt a fejlett nyelvi modellek hasznosak lehetnek a kereskedők számára, hiszen nagy mennyiségű adat értelmezését könnyíthetik meg, tehetik feldolgozhatóvá. Az egyre újabb változatok nagyságrendi ugrásokat jelentenek, bár várhatóan a fejlődés ezen a téren nem lesz ilyen ugrásszerű a jövőben. Emellett arra is láthatunk bizonyítékokat, hogy a gyorsjelentésekben valóban vannak olyan információk elrejtve, melyek a jövőre vonatkozóan a kereskedő hasznára válhatnak.
Mire számíthatsz, ha a ChatGPT ad pénzügyi tanácsot?
Érdemes szem előtt tartani, hogy a ChatGPT betanítása könyveken, internetes adatbázisokon történt, így biztosra vehetjük, hogy a befektetési portfólió kialakításának ismereteivel, többek között a hatékony piacok elmélete, a modern portfólióelmélettel tisztában van az algoritmus. A kérdés ezek után, hogyan tud megfogalmazni befektetési tanácsokat a ChatGPT.
A Using GPT-4 for financial advice cím alatti vizsgálatban négy különböző kockázati profillal rendelkező befektető nevében kértek befektetési tanácsot. A kockázati profilok fő jellemzői az alábbiak voltak:
- Hosszú távú befektető, alacsony kockázati tolerancia
- Hosszú távú befektető, magas kockázati tolerancia
- Rövid távú befektetők, alacsony kockázatvállalási hajlandóság
- Rövid távú befektető, magas kockázatvállalási hajlandóság
Az alábbi táblázat összefoglalja a négy befektetői profil sajátosságait az életkor (Age), befektetési időtáv (Investment horizon), kockázatvállalási hajlandóság (Risk tolarence) tekintettében.

A fentiek után minden egyes kockázati profilhoz egy optimális portfólióallokációt kértek a ChatGPT 4-es verziójától. Az alábbiakban idézett rész a feltett kérdést reprezentálja, ahol a zárójeles részek voltak a változók az egyes kockázati profilok esetében:
I am [age] years old and live in the United States of America. I am investing for retirement over a [investment horizon]-year horizon, and have a [risk tolerance] risk tolerance. Which specific financial products (including ticker and provider)
would a typical financial advisor recommend for investment given my circumstances? Which composition (as a percentage) would he recommend for each financial product? I will not consider your response personalized advice.
A ChatGPT válaszaiból gyorsan megállapítható, hogy figyelembe vette a befektető befektetési időtávját, életkorát és kockázatvállalásai hajlandóságát. Ez egyúttal azt jelenti, hogy magas kockázatvállalási hajlandóság és hosszú befektetési időtáv esetében részvénytúlsúlyos portfóliót ajánlott a befektetőnek, továbbá a javaslatai között szerepelt a költséghatékonyság, azaz alacsony alapkezelési díj mellett működő, jól ismert alapkezelők ETF alapjait ajánlotta a kérdező részére. Emellett az is megfigyelhető volt a válaszokban, hogy az ajánlás egyes elemeit magyarázatokkal támasztotta alá.
Az amerikai piacon ma már számos „automata” befektetési tanácsadást nyújtó társaság szolgáltatása érhető el. Az iparág jelenleg 50 milliárd dollárnyi vagyont kezel. A szolgáltatás lényege, hogy egy összetett kérdőívvel mérik fel a befektető profilját, majd ezek alapján automatikusan készül el a portfóliójavaslat. Ebben a rendszerben nincs gépi tanulás. Mindössze a befektetési alapelvek vannak szabályok formájában összegezve, és a kérdőívre adott válaszok alapján, a szabályok segítségével generálódnak le a portfóliójavaslatok. Az alábbi táblázat alsó sorában láthatjuk az automata befektetési tanácsadással generált portfóliókat a négy kockázati profillal összevetve.

A hasonlóság szembetűnő, azaz a ChatGPT (felső sor) hasonló elvek szerint alakította ki a portfóliót. Ugyanakkor a ChaGPT által összerakott portfóliók sokkal jobban szenvednek a home bias torzításában, azaz nagyobb az aránya (70% az első portfólióban) az amerikai (domestic) részvényeknek. Globálisan ugyanis az amerikai részvénypiac kb. a 50-60 százalékát teszi ki a részvénypiacoknak. Ezzel párhuzamosan a nemzetközi részvénypiacok és a fejlődő országok részvénypiacai alulsúlyozásra kerültek. Köztudott, hogy az amerikai befektetési tanácsadók véleményét erősen eltorzítja a home bias (részletesen itt beszéltünk arról, hogy az amerikai adatok miért torzítanak), és vélhetően a ChatGPT betanítása is ezeken a torzított adatokon történt.
Az alábbi táblázatban az ajánlott portfóliók eredményei tekinthetők át. Mivel egyes eszközökről csak 2016-tól álltak rendelkezésre adatok, így a 2016-2023 közötti időszak eredményeit látjuk. A bal oldalon az SR oszlopban a ChatGPT ajánlásával készített portfóliók sharpe-rátái, a jobb oldali oszlopokban az automata, roboadvisorok eredményei láthatók.

Egységnyi kockázatra vetített hozamban felülteljesítettek a ChatGPT által összerakott portfóliók, de a rendkívül rövid időtáv miatt messzemenő következtetéseket nem érdemes levonni ebből. Az alábbi képen a ChatGPT portfólióinak eredményei követhetők nyomon.

Itt pedig a hagyományos automata befektetési tanácsadók portfóliói láthatók.

Összegezve a fentieket, azt láthatjuk, hogy a ChatGPT képes olyan befektetési tanácsokat adni a rendelkezésére álló információk alapján, melyet a hagyományos befektetési tanácsadók adnának. Vegyük figyelembe, hogy az automata befektetési tanácsadók kérdőívek alapján mérik fel a befektető profilját, és előre meghatározott szabályok szerint alakítanak ki ügyfeleiknek portfóliót. Tehát gyakorlatilag automatizálják a hagyományos befektetési tanácsadást.
Az adatokból kitűnik, hogy a ChatGPT javaslatait is eltorzítja a home country bias, mely vélhetően összefügghet azzal, hogy a betanítására használt adatokat is eltorzítja ez a jelenség. A fentieken túl azt is láthattuk, hogy a ChatGPT képes tanácsai során figyelembe venni a kérdező kockázatvállalási hajlandóságát, életkorát, befektetési időtávját, melyek lényeges információk a portfóliókialakítás során.
A ChatGPT jobban értelmezi a Fed sajtótájékoztatókat..
Országok központi bankjai rendszeresen tartanak sajtótájékoztatókat, melyben a gazdasági élettel, a befektetési eszközökkel kapcsolatban nélkülözhetetlen információk hangzanak el. A központi bankok közül külön kiemelhető a Fed, az amerikai jegybank szerepét betöltő szervezet, hiszen a globális kamatok (dollár) és a globális gazdaság szempontjából az egyik legnagyobb hatást gyakorló központi bankról beszélünk, melynek döntéseihez a világ számos más jegybankja kénytelen bizonyos fokig igazdoni. Sajnos azonban az átlagember számára a jegybanki sajtótájékoztatók nehezen érthető események, és az igazat megvallva sokszor nincs is feltétlenül összefüggés az elhangzott mondanivalóban, ahogy ezzel kapcsolatban a Fed egyik korábbi elnöke, Alan Greenspan is nyilatkozott:
“Since I’ve become a central banker, I’ve learned to mumble with great incoherence.”
A fentieket úgy fordíthatjuk le, hogy „Mióta jegybankár lettem, megtanultam nagy tanácstalansággal motyogni.”
Mindenesetre a Can ChatGPT Decipher Fedspeak? cím alatti vizsgálat szerzői 2010-2020 közötti időszakon tesztelték különböző nyelvi modellek értelmező képességét, és arra voltak kíváncsiak, hogy az elhangzott Fed sajtótájékoztatók alapján milyen pontosan tudják megállapítani a monetáris politika irányvonalát, melynek alapvetően öt állapotát különíthetjük el:
- Dovish: erős galamb hangvétel, azaz erős vélemény a jegybank részéről, hogy túl lassan nő a gazdaság, stimulusra van szükség.
- Mostly dovish: főleg galamb hangvétel, azaz az az általános vélemény a jegybank részéről, hogy túl lassan nő a gazdaság, stimulusra van szükség.
- Neutral: semleges jegybanki hangvétel.
- Mostly Hawkish: főleg héja hangvétel, azaz az az általános vélemény, hogy hogy a gazdaság túlfűtött, túl gyorsan növekszik.
- Hawkish héja hangvétel, azaz erős utalás arra, hogy a gazdaság túlfűtött, túl gyorsan növekszik.
Az alábbi grafikonon látható, hogy különböző nyelvi modellek az emberekhez képest (human oszlop), milyen pontossággal tudták értelmezni a Fed sajtótájékoztatókat. Jól látszik az adatokból, hogy a ChatGPT 3-as verziója lényeges javulást mutat a többi nyelvi modellhez képest. A szerzők megállapítása között szerepel, hogy a fentiek alapján arra számíthatunk, hogy a ChatGPT 4-es modellje még pontosabban tudja értelmezni a Fed közleményeket.

ChatGPT és a részvényárak jóslása
A Can ChatGPT Forecast Stock Price Movements? Return Predictability and Large Language Models cím alatti vizsgálatban már a ChatGPT 4-es verzióját is vizsgálták, és összevetették a korábbi verziókkal. Ebben az anyagban egy rövidebb időszakon elemezték a megjelenő hírek és a részvények jövőbeni hozama közötti kapcsolatot. A nyelvi modellek feleadat az volt, hogy megállapítsák a hír pozitív vagy negatív volt a kapcsolódó társasággal összefüggésben, és ezen jelzések alapján alakítottak ki portfóliót. A portfólióba egyenlő arányban kerültek be az érintett részvények úgy, hogy a pozitív hangulatú hírek esetében vétel, a negatív hangulatú hírek esetében eladási pozíciót nyitottak (long-short portfólió részletei itt). Mindegyik módszernél napi rendszerességgel rebalancingot hajtottak végre, kereskedési költségeket nem vettek figyelembe.
Az alábbi grafikonon a zöld görbe annak a stratégiának az eredményt mutatja, mely a ChatGPT 3.5 verziójának hírértelmezése alapján alakította ki a portfóliót. Ebben az esetben a pozitív hírek esetén megvásárolták a részvényeket (long only változat). A piros görbe annak a stratégiának az egyenlege, mely negatív hírek esetén short pozíciót indít, a ChatGPT 3.5 verziója alapján. A világoskék görbe ugyanúgy a ChatGPT 3.5 jelzésén alapult, de már long-short portfólióval. A sötétkék görbe a ChatGPT 4.0 long-short eredményeit mutatja. A sárga görbe a piaci portfóliót reprezentálja.

Különböző tranzakciós költségek függvényében változik a kinyerhető hozam, lásd alábbi grafikonon.

Jól látható a fentiekből, hogy a ChatGPT az elődjénél nagyobb pontossággal tudta megállapítani a megjelenő hír társaságra gyakorolt negatív, pozitív hatásait. Emellett pedig arra láthattunk példát, hogy a ChatGPT a részvénypiaci kereskedés, befektetés során is hasznos eszközzé válhat.
A témát itt folytatjuk: Miért téved, hibázik a mesterséges intelligencia?
Ha kérdésed van a fentiekkel kapcsolatban, hozzá szeretnél szólni a témához, csatlakozz facebook csoportunkhoz ide kattintva!
Tanfolyamaink:
- Befektetési alapismeretek, stratégiák, részletek itt.
- Tőzsdei kereskedés magyar és külföldi piacokon, részletek itt.
- Rövid távú, daytrade kereskedés devizákkal, részvényekkel, részletek itt.
- Bitcoin és kriptoeszközök képzés, részletek itt.